Taming False Discoveries with Empirical Bayes
How to safely fish in a sea of noise
This article previously appeared on medium
Todays data scientist have an enormous amount of data at their disposal. But they also face a new problem: With so many features to choose from, how do we prevent making false discoveries?
p-values lend themselves to false discoveries. Assuming that there is no effect, running 100 independent p-value tests will yield 5 positive outcomes on average. Being misled 5 times is manageable, but if we run millions of hypothesis tests, the situation quickly becomes unbearable.
We need a method that allows us to control the amount of false positives we find. It should scale with the number of hypothesis we run and allow us to be confident about our findings as a whole.
The Scenario
You work at a big data science company which is in the business of predicting the outcome of horse races. You and your colleagues collect data on horses, stadiums, jockeys, and so on and then build models. Those models in turn inform betting strategies. Over time, you and your colleagues have developed 60,000 strategies. Your task is to find strategies whose true winning ratio is above 50%. While this is of course a simplified problem, there are many applications that are quite close, such fMRI in Neuroscience, microarrays in genetics and alpha-measurement in finance.
Below you see the data: n_games describes the number of bets taken with a strategy. won describe how often the strategy won and ratio is the share of games won. Because this is synthetic data, we know if a strategy’s true ratio is above 50%. In real life, you would have no access to the true value, but it will be helpful later.
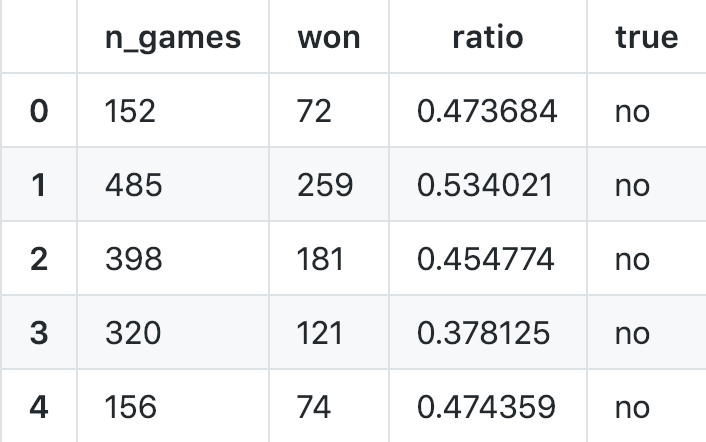
The plot below shows the distribution of observed win-ratios of all strategies. As you can see, there are quite a few strategies with a win-ratio over 0.5.
The problem is that most of the strategies with high observed win-ratios will display them only by chance. We know that most strategies do not have a win-ratio over 0.5. It is clearly evident in our data. We need to find a way to incorporate this indirect evidence into our result. Good thing that a certain reverend Bayes thought about this problem in the 18th century.
A Matter of Belief
The concepts introduced in this text broadly belong in the area of Bayesian Statistics. The key concept is that we are not as only interested in the distribution of data, but also in the distribution about beliefs about true, unobserved values. The true win-ratio of each strategy is unobserved. But we can form an estimate of what the true win-ratio might be. Because we are not 100% sure about our estimate, we think that multiple values could be true, but do not assign all of them the same probability of being true.
In our daily lives, we do this intuitively. If I asked you what the weather in the Sahara will be tomorrow, you would say: “Probably sunshine, it hardly ever rains there”.
The belief we have before we have seen any data is called the prior belief (prior, aka before, to seeing data). Your belief about the weather in the Sahara was formed without any information about what it is like in the Sahara right now.
Once we observe data, we can update our beliefs. If I told you that huge rain clouds have sighted over the Sahara and that meteorologists are excited for an event of the decade, your answer about the weather would change. You might say “Perhaps it rains, perhaps not. 50/50”. This new and updated belief is called the posterior belief (posterior, aka after, to seeing data. Fancy old english).
Mathematically, Bayes’ Theorem formulates an update rule, so we can not only intuitively update our beliefs, but also quantitatively. For this we need data and, crucially, a prior.
Empirical Bayes
Back to our betting strategies, what should our prior belief about the win-ratio of betting strategies be? In the Sahara example, we had a strong prior based on our knowledge of deserts. In the betting example, we only have data and no prior information.
The key idea behind the Empricial Bayes method is to use all of our data to form our prior and then data from specific strategies to form posterior beliefs about the true win-ratios of the different strategies.
In our case, we assume that our belief about a strategies win-ratio can be expressed using a Beta distribution. This means that we don’t think there is one true win-ratio but a distribution of win-ratios. The distribution can be described using two parameters, alpha and beta. We can infer the most likely values to have produced our data using scipy’s beta function:
alpha_prior, beta_prior, _, _ = ss.beta.fit(df['ratio'], floc=0, fscale=1)
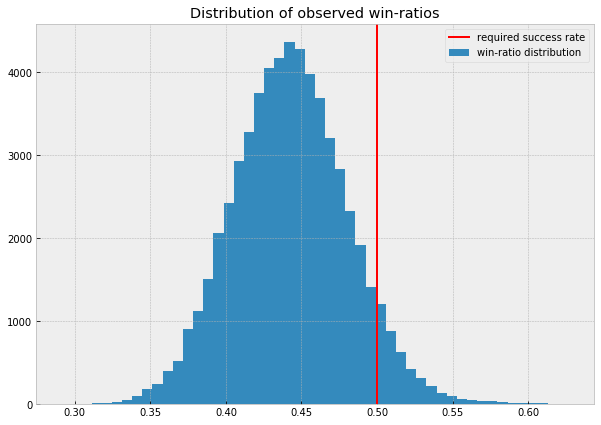
With the alpha and beta priors in hand, we can sample from our prior to see that it matches the data. Below you can see the data in blue and the inferred prior distribution in orange.
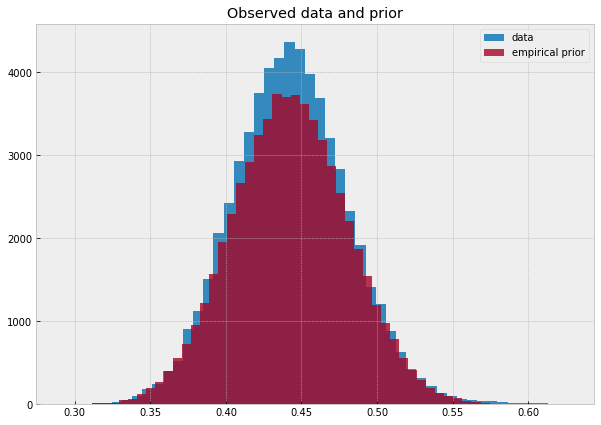
We can also compute the average win-ratio under this prior:
prior = alpha_prior / (alpha_prior + beta_prior)
print(f'Expected win ratio under prior: {prior*100:.2f}%')
Expected win ratio under prior: 44.27%
Can we just estimate a prior like that?
Let’s step back here, because what we just did has the flair of some made up stats. Because we lacked a prior that was rooted in knowledge, we just… made one up? That can’t be right. But there is an intuitive as well as mathematical logic to this. How did you know that there is little rain in the Sahara? You probably read something written by a geographer who relied on centuries of observations by people and perhaps even artifacts that date back millenia. Based on all that data, the geographer formed the opinion that there is little rain in the Sahara, and you believed it. How is the process of believing the geographer who collected lots of data different from collecting data ourselves?
There is one potential difference and that is that that the geographer collected data on something related to, but ultimately independent from, the object of our study. The geographer did not collect data on if it will rain tomorrow, but only on the general weather in the Sahara. Equally, if we want to use data from the other strategies to inform decisions about any specific strategy, the win-ratios have to be independent of each other. This is also a key assumption the mathematical justification makes (the technical term is that the data has to come from parallel situations. It also has to be sufficiently large).
Updating Our Beliefs
Now that we invested hard work to form a prior, it is time to use the data about individual strategies to form posteriors. For beta distributions, the update rule is relatively straightforward. The posterior of the alpha parameter equals the number of games won by the strategy plus the prior value of alpha.
df['alpha_posterior'] = df.won + alpha_prior
The beta parameter equals the number of games lost by the strategy plus the beta prior.
df['beta_posterior'] = (df.n_games - df.won) + beta_prior
The chart below shows the prior distribution as inferred from the data (blue) and the posterior of one specific strategy (red). As you can see, this strategy has most of its posterior values above the required win-ratio. In other words, most of the true win-ratios we think are possible are above the line.
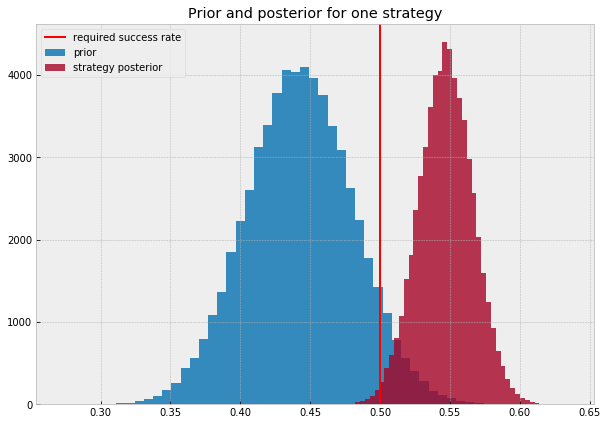
Shrinkage
Because we take the overall mean win-ratio into account when estimating the true win ratio of each strategy, we “shrink” our estimates towards the grand-mean. Empirical Bayes is a so called “shrinkage” method. As we will see later this is precisely what helps us to reduce false discoveries: We bias our estimates towards finding nothing.
To visualize the shrinkage, let’s calculate the mean posterior win-ratio for each strategy:
df['eb_ratio'] = df.alpha_posterior / (df.alpha_posterior + df.beta_posterior)
The plot below shows the distribution of win-ratios in the data (blue) and the distribution of estimated true win-ratios for all strategies (red). As you can see, the estimates are all closer to the mean and there are significantly fewer strategies whose estimated win-ratio is over the requirement (red line).
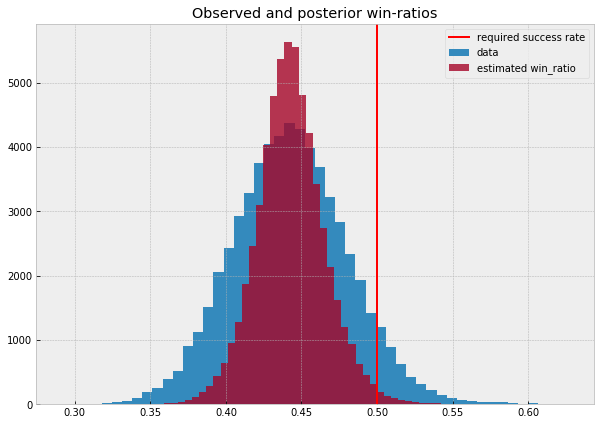
Of course, not all estimates are shrunk by the same amount. We would expect to shrink estimates for which we have more data (speak, which strategies we tried on more games) less than strategies for which we have only little data. This is exactly what is happening. Bayes Rule takes in account the amount of evidence we have for a posterior that might be different from our prior.
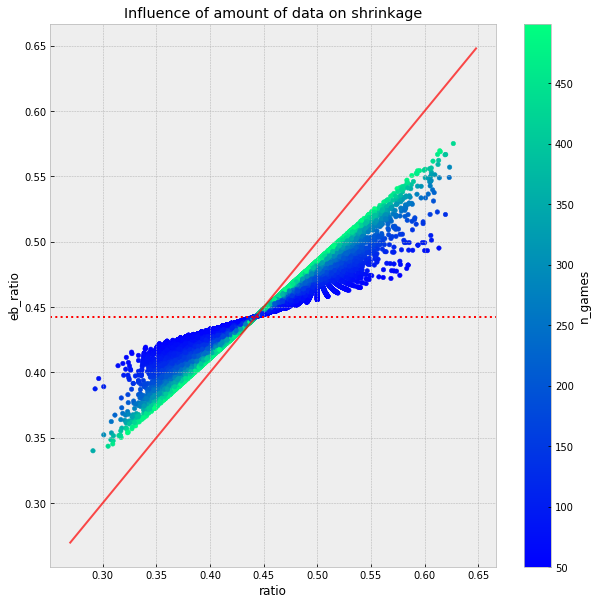
The chart below shows the relationship between shrinkage and the amount of data we have. The solid red line is the line at which the observed win ratio is the estimated win ratio. If a point is near the solid red line there is only little shrinkage. The dashed red line is the prior. Green dots are strategies for which we have a lot of data, blue dots are strategies for which we have only little data.
As you can see, strategies for which have little data (blue) are closer to the prior and further away from the observed value. Strategies for which we have a lot of data (green) are shrunk less towards the prior.
False Discovery Rates
As we saw earlier, we do not only estimate one true win-ratio for each strategy. We estimate an entire distribution of win-ratios we deem possible. This was a lot of extra work, but it greatly simplifies the question we came here for: “How likely is it that the strategy is a false discovery, and the true win-ratio is below 0.5?”
To answer this, we can ask ourselves: “What share of our posterior belief distribution for our strategy is below 0.5?”
The chart below shows the posterior belief distribution of a strategy. The red line is the critical hurdle of 0.5. The orange area shows the part of the belief distribution that is below the hurdle. Under our belief, the probability that the true win-ratio is less than 0.5 is the orange area.
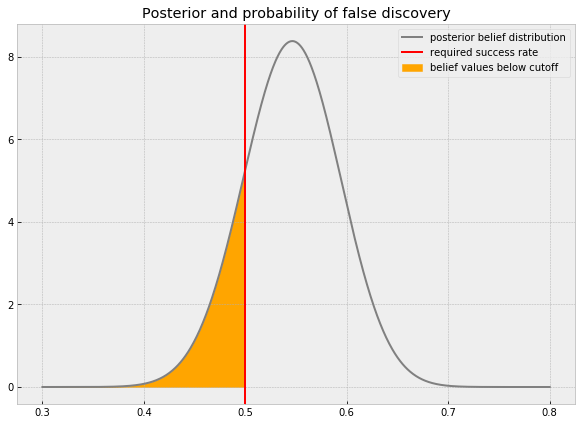
We can compute the area, and thus the probability that this strategy is a false discovery, with the cumulative density function of the beta distribution.
print(f'The probability that this strategy is a false discovery is {ss.beta.cdf(0.5,60,50)*100:.3} %')
The probability that this strategy is a false discovery is 16.9 %
This method can be applied to all strategies to find out the likelihood that they are a false discovery:
df['FDR'] = ss.beta.cdf(0.5,df.alpha_posterior,df.beta_posterior)
Managing the Overall False Discovery Rate
Now how do we choose which strategies to make bets with? We could simply pick strategies that have a low probability of being a false discovery by themselves. But we can do better. Because of the linearity of expectation, the expected rate of false discoveries of multiple strategies is the sum of the individual probabilities of being a false discovery. E.g. if we have ten strategies with a 1% probability of being a false discovery, then the expected share of false discoveries in those ten strategies is 10%.
We can thus choose which share of false discoveries we find acceptable. Let’s say, in our betting business we are fine if 5% of our deployed betting strategies do not have a true win-ratio above 0.5. We can then sort the strategies by their individual probability of being a false discoveries and choose those that cumulatively have a false discovery rate of 5%.
accepted = df[df.FDR.cumsum() < 0.05]
Since this is synthetic data, we can check how well this worked, and indeed, we find that about 5% of our strategies do not actually have a sufficient win-ratio. As you can see, our estimate is pretty close!
print(f"The actual false discovery rate is {(len(accepted[accepted.true == 'no']) / len(accepted)*100):.2f}%")
The actual false discovery rate is 5.26%
Epilogue
In this text you have seen the basic building blocks of the Empirical Bayes framework and how you can use it to manage your false discovery rates.
Empirical Bayes belongs to a broader family of shrinkage methods which are all ways of regularizing. Regularization is a common theme in machine learning so you might have encountered it in the context of ML before. Whenever you run the risk of making a false discovery, be it an overfit set of parameters in a deep learning model or a humble win-ratio, it is useful to bias your findings towards finding nothing. Often, this works with a method strongly related to Empirical Bayes, such as in ridge regression.
As data science moves into more and more high-stakes applications where a false discovery or an overfit model can have catastrophic consequences, regularization becomes more and more important.
Further Reading
The Jupyter notebook with all code can be found here. This text is part of my study notes for Bradley Efron and Trevor Hastie’s “Computer Age Statistical Inference” which covers this and other topics in much more detail. Efron also wrote a book purely on Empirical Bayes “Large Scale Inference”. David Robinson has written a more code driven introduction. My work, ML for finance, discusses some of the questions raised in this text in a financial context.